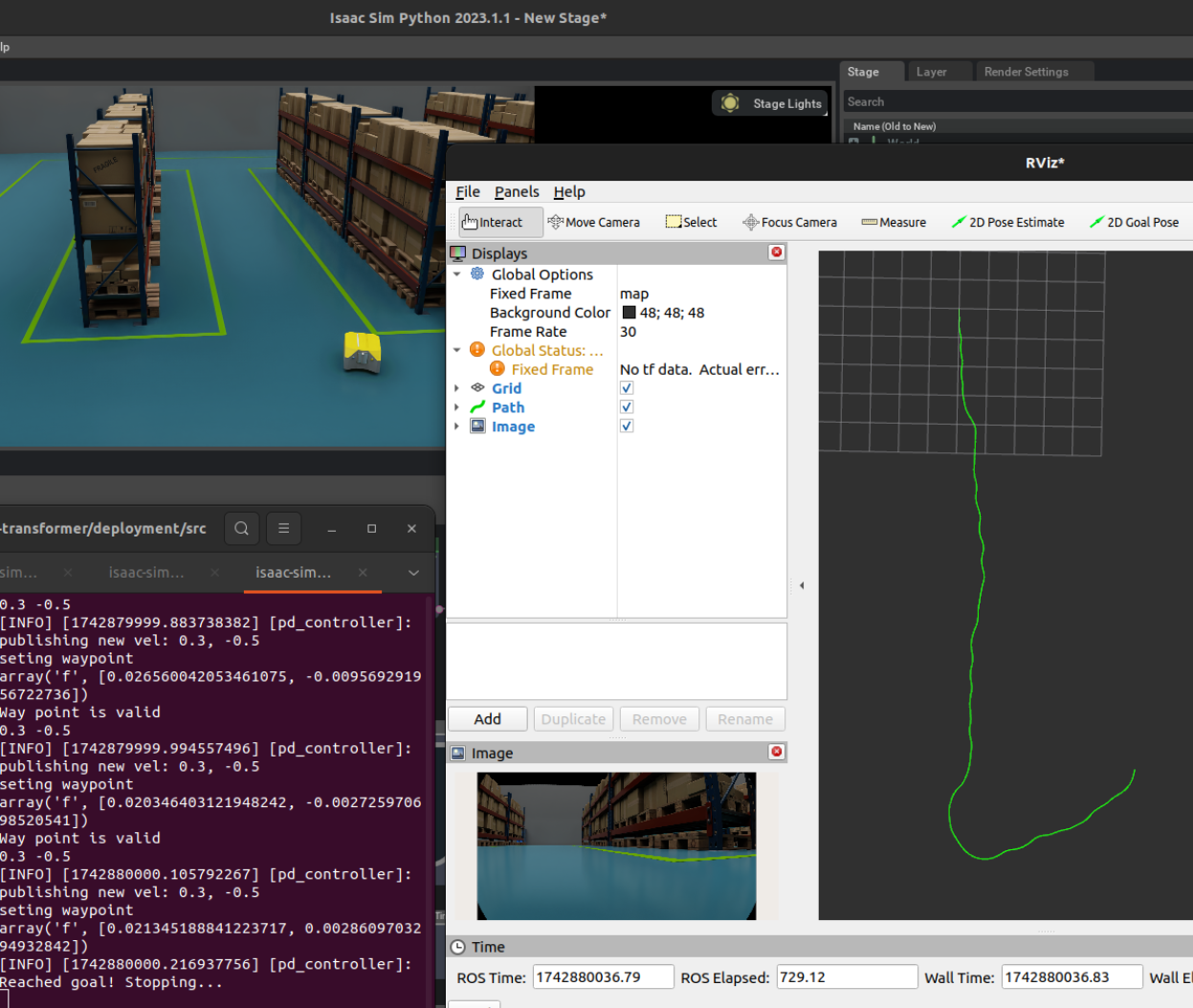
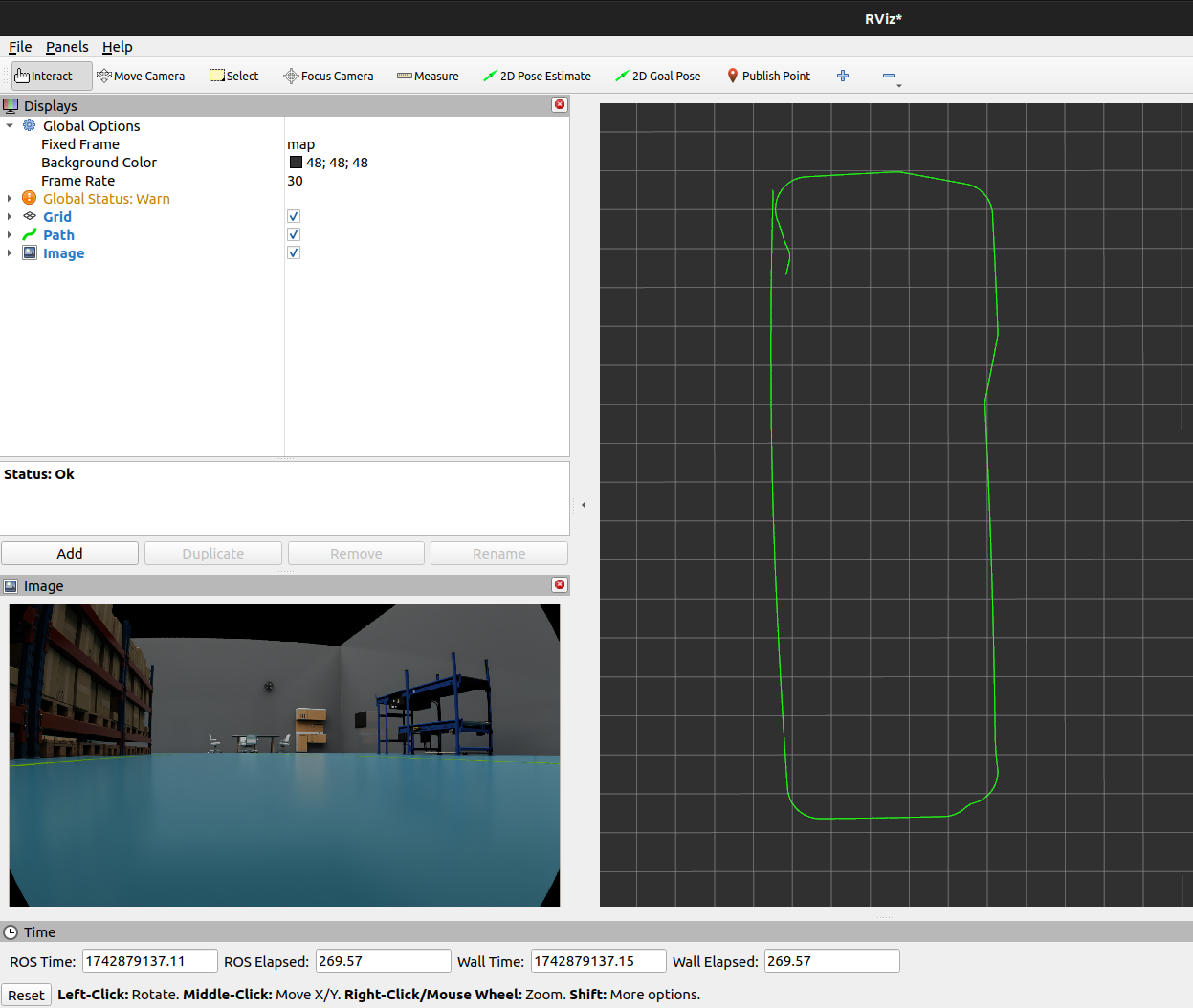
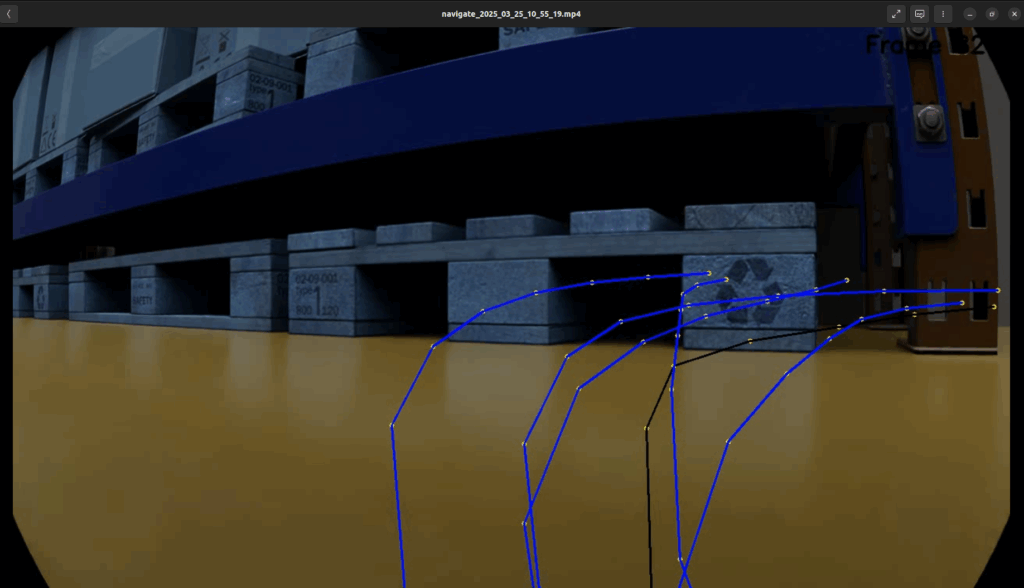
- Smoother motion
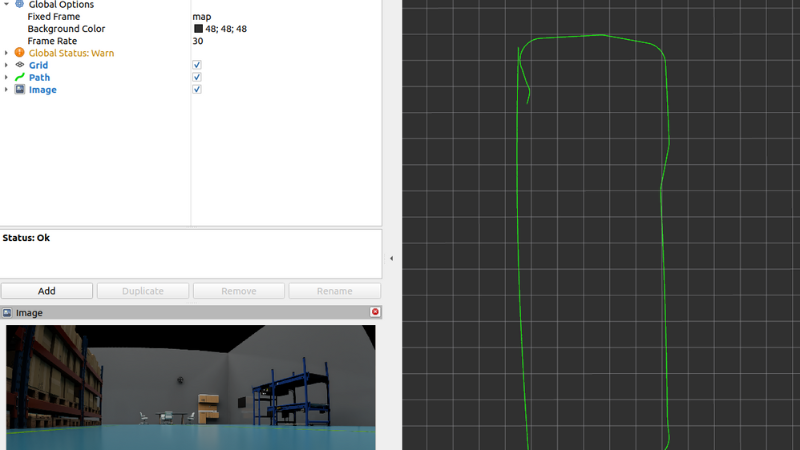
Traditional path planning produces smooth, optimal trajectories. Both ViNT and NoMaD generated noisy actions with unnecessary angular velocity variations, even for straightforward goals. Using a better tracker to ensure we reach the waypoint could also help mitigate this.
Recent Research:
Several more recent approaches attempt to address the current limitations in robot navigation. One promising direction is using models like NaviDiffuser, which generate entire action sequences instead of just single-step actions. This enables longer-term planning that considers multiple objectives such as safety, efficiency, and operational cost.
To improve obstacle avoidance, the CARE framework enhances navigation by combining ViNT with depth estimation and a local costmap, changing trajectories to replan around obstacles or immediately avoid them.
Recent work like NaviBridger holds promise for smoother and smarter actions by denoising previous actions rather than denoising random actions from scratch for each frame.
Safety is also being tackled through hybrid approaches like Risk-Guided Diffusion, which fuses a fast, learned policy with a slower, physics-based controller. This balances the adaptability of foundational models with the reliability of formal safety guarantees.
In service-oriented scenarios, object-based navigation like LM-Nav leverages visual language models to identify landmarks in images, constructing a navigation graph and planning paths to specific goals. While not ideal for repetitive warehouse automation, this technique offers significant value in object-rich environments.
Another innovative approach is LLM-guided planning, where large language models use their commonly known knowledge of the world to inform navigation. This semantic understanding acts as a powerful heuristic, enabling more intelligent and context-aware decision-making.
Future Directions
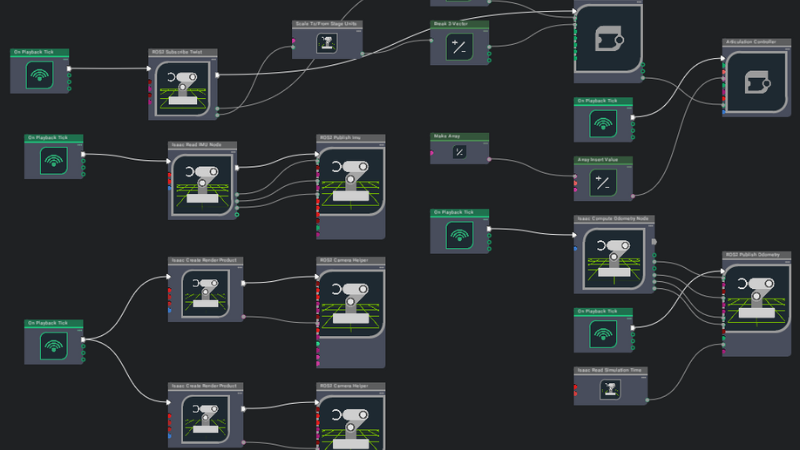
Testing ViNT and NoMaD on the Sherpa-RP, our mobile robot platform for autonomy research, showed us both the potential and current limitations. They helped us understand what are the needs that have to be addressed for real world applications and how they are being solved or thought about in the latest research publications.
We are actively researching
- Hybrid approaches supplementing the explored models with active feedback
- Generating synthetic warehouse training data for finetuning these models
- Multi-modal models with depth and IMU fusion
The future does lie in thoughtful combinations of traditional and learned models utilising the strengths of both. As researchers continue pushing boundaries and addressing current limitations, we are optimistic about the eventual realization of truly general robotic navigation systems.
References
- ViNT: A Foundation Model for Visual Navigation – https://arxiv.org/abs/2306.14846
- NoMaD: Goal Masked Diffusion Policies for Navigation and Exploration –
https://arxiv.org/abs/2310.07896
- NaviDiffuser: Cost‑Guided Diffusion Model for Visual Navigation –
https://arxiv.org/abs/2504.10003
- CARE: Enhancing Safety of Foundation Models for Visual Navigation through Collision Avoidance via Repulsive Estimation – https://arxiv.org/abs/2506.03834
- NaviBridger: Prior Does Matter – Visual Navigation via Denoising Diffusion Bridge Models – https://arxiv.org/abs/2504.10041
- Risk-Guided Diffusion: Toward Deploying Robot Foundation Models In Space, Where Failure Is Not An Option – https://arxiv.org/pdf/2506.17601
- LM-Nav: Robotic Navigation with Large Pre-Trained Models of Language, Vision, and Action – https://arxiv.org/abs/2207.04429
- Navigation with Large Language Models: Semantic Guesswork as a Heuristic for Planning – https://arxiv.org/abs/2310.10103